clingo
When you use a package manager, how does it work? Or more generally, have you ever been interested in solvers? This week we showcase clingo, a grounder and solver for logic programs. It’s a fundamental tool to allow you to learn and do Answer Set Programming (ASP). If you are doing research software engineering in the direction of innovating research software, this library will be of interest to you. Why? Because we very likely can model existing methods with answer set programming to create new tools and ideas.
If you are already familiar with this software, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
podman
This week for the RSEPedia showcase, we are highlighting another rootless container technology that is empowering developers and researchers to use containerization, podman!. We also want to point out that this week is the Container Plumbing Days conference, a free event where you can register and attend talks about everything from container building, to security, and standards. Woohoo!

If you are already familiar with this software, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
jsonschema
For our RSEPedia showcase this week, let’s celebrate a library that has been empowering our json and yaml associated with Python projects for years to be parsed and verified as correct… jsonschema!
If you are already familiar with this software, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
libabigail
Our spotlight this week is on libabigail, the ABI Generic Analysis and Instrumentation Library, a C++ library for creating and otherwise interacting with ABI artifacts. What are these artifacts? When you compile code into a binary, the binary basically keeps signatures for types, variables, functions, and variables. All of these together are called an ABI corpus, and we can inspect the corpus for a binary to see if it’s compatible with another library or system of interest, to inspect changes, or even to use them as features for some machine learning oriented approach. I’ve been using and hacking on this library and want to share with you my excitement for the set of tools.
geopandas
For our RSEPedia showcase this week, we want to direct your attention to GeoPandas!

If you are already familiar with this software, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
3dfier
In the world of research software, we have a strong expectation about the kinds of libraries that we might see. There are many different kinds of tools for parsing datasets, or a domain specific utility, along with statistical or other numerical tools. But when visualization is thrown into the mix, or using a data file in a way that is surprising and unexpected? These are the kinds of repositories that are so different and unique that they capture our attention we have to share it! This is exactly the case with the library for the software showcase this week - tudelft3d/3dfier!
Delft in 3D by TU Delft from Filip Biljecki on Vimeo.
The quick video above can give you a sense of what this software is capable of doing - starting with basic maps and point clouds, and generating a beautiful rendered 3D scene, which might be what you’d guess based on the name “3dfier.” If you are already familiar with this software, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
anTraX
The software we want to share this week is really neat - here we present Social-Evolution-and-Behavior/anTraX!
The image above comes directly from the arXiv supplementary material publication from the authors. You can probably guess from the above what the software does - we are tracking ants (or other small friends) to better understand their movement or behavior. Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
curl
One of the aims of the Research Software Encyclopedia is to bring attention to libraries that we take for granted. The ones that easily come to mind are git and Linux, but today’s showcase honors another open source library that you’ve probably used and taken for granted - curl! Some might argue that this library is not qualified to be called research software, but we could probably agree that is plays an import role in the research ecosystem, which is why we want to showcase it today.

Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
retriever
Can you imagine a database of datasets paired with a tool to automatically download, preprocess, and import into a desired format for your usage? For this week’s RSEPedia Software Survey, we introduce you to weecology/retriever, a tool to do just that.

Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
optuna
Hyperparameter tuning has been around as long as any major cornerstone of machine learning. So why another package for tuning hyperparameters? This week on the Research Software Showcase we share optuna, which we assure you is worth trying out if you need to do this kind of optimization.

Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
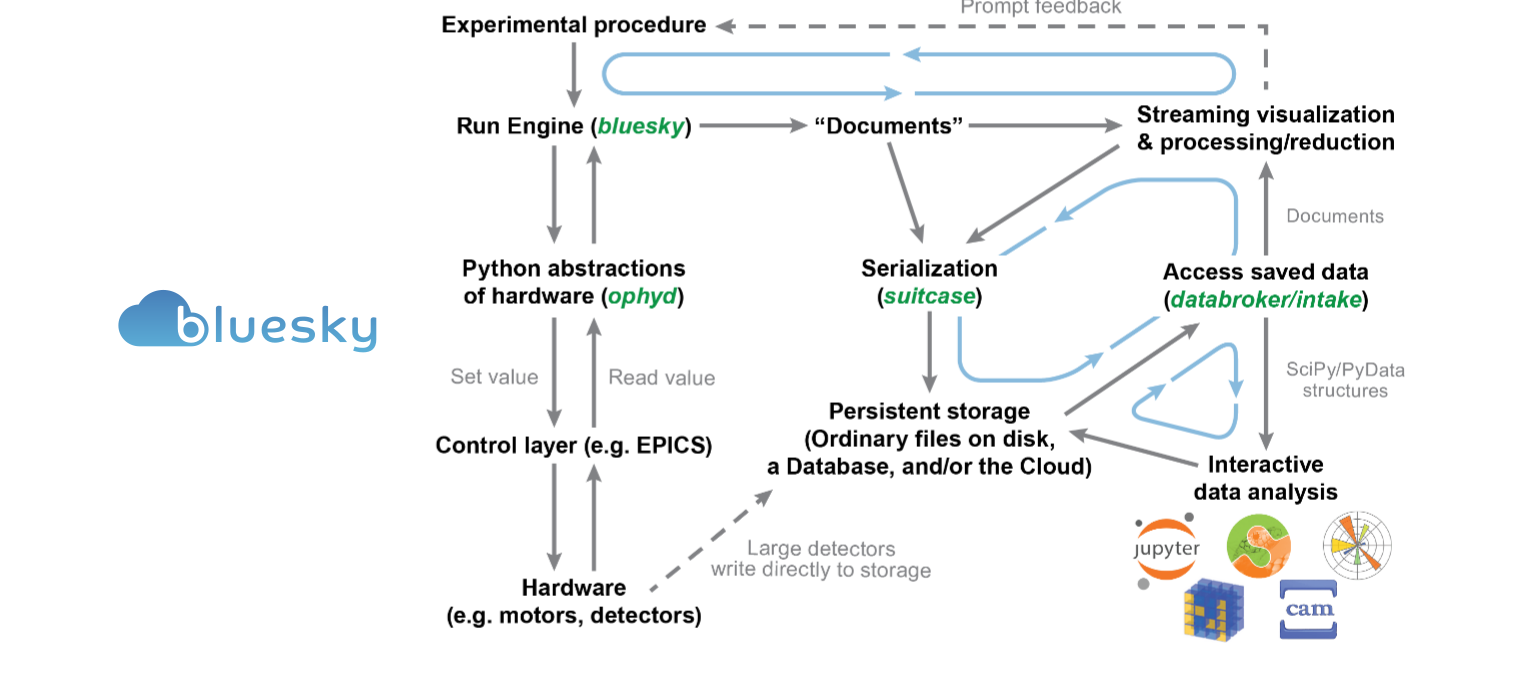
bluesky
This week for the Research Software Encyclopedia Software Showcase we move into the world of experiment orchestration and data management. This includes features like:
- streaming data
- metadata
- cross-hardware compatibility
- interruption recovery
- suspend or resume
- exportable formats
- customization
- interface with scientific python
If you too are like me and have never tried a library like this, I recommend starting with the tutorial.
Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
medrxivr
If you’ve ever done some kind of literature analysis, you’ve probably also done some web scraping to retrieve content, or otherwise struggled with ancient APIs to download some subset of data. If you are particularly interested in preprints for medicine, then you might have heard of MedrXiv, a database of preprints for health sciences. Forget about scraping this server, a newly published tool from ROpenSci called medrxivr is all you need to download preprint data.

Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
self-hosted-runners
Did you know that you can use self hosted runners for GitHub actions? For this non-traditional research software showcase, we want to introduce you to ci-for-science/self-hosted-runners, a repository of recipes to help you get started with your own self hosted runners!
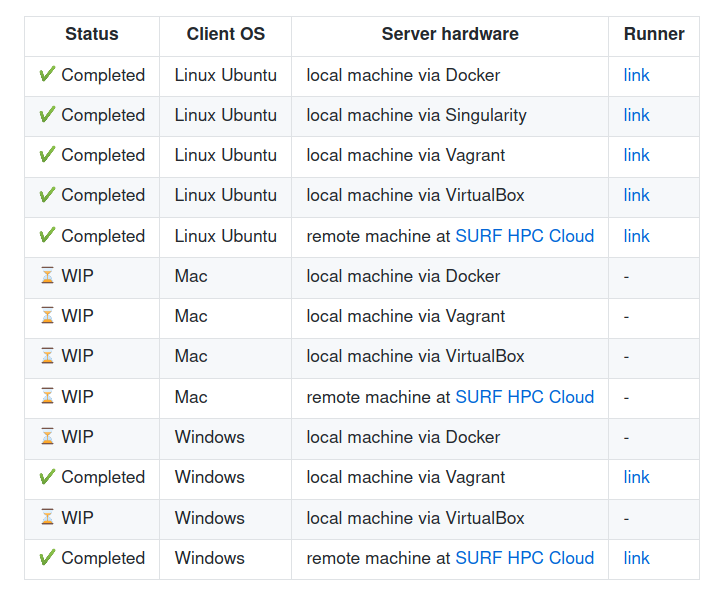
Are you already familiar with self-hosted-runners? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
nodepy
Nodepy is a package for the analysis of numerical ODE solvers. Why is an ODE solver? Read on to learn more!
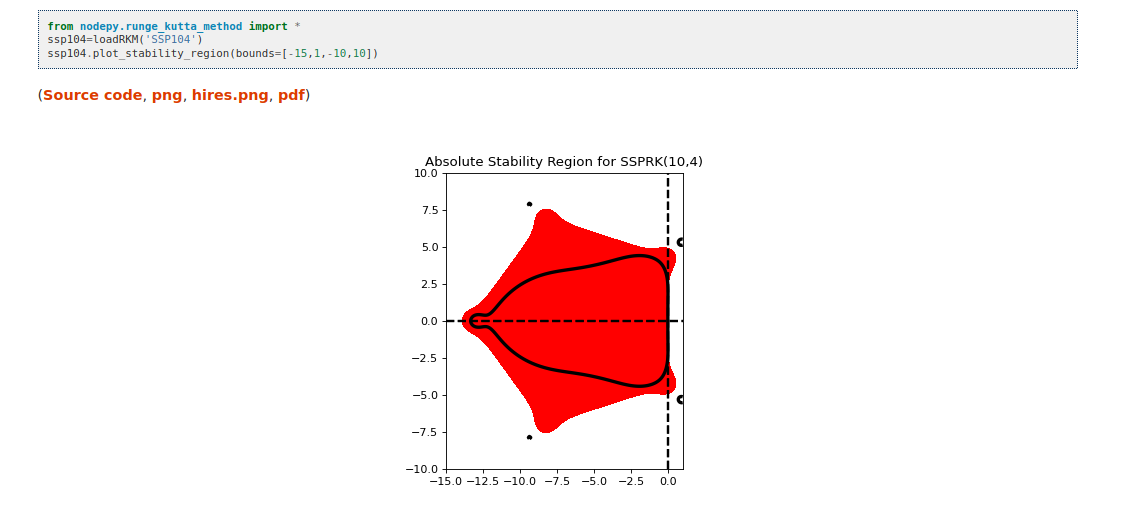
Are you already familiar with nodepy? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
VRPy
Today we’ll take a detour (pun intended) into the vehicle routing problem, and present VRPy, a Python library for solving several variants of this problem.
Are you already familiar with VRPy? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
AstroPaint
Do you have an opinion? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
ann-benchmarks
Today’s post is all about benchmarking. We’ll focus on erikbern/ann-benchmarks, which is project used to evaluate approximate nearest neighbor searches (ANN).
What is ANN? In many applications we want to solve the nearest neighbor problem – given some point in the dataset, what are other points closest to it? For example, if you are listening to one song in a dataset and want recommendations for similar songs, you might want to look at its nearest neighbors! People have found ways to speed up nearest neighbor searches using approximation methods, which are often good enough. Hence, ‘Approximate Nearest Neighbors’!
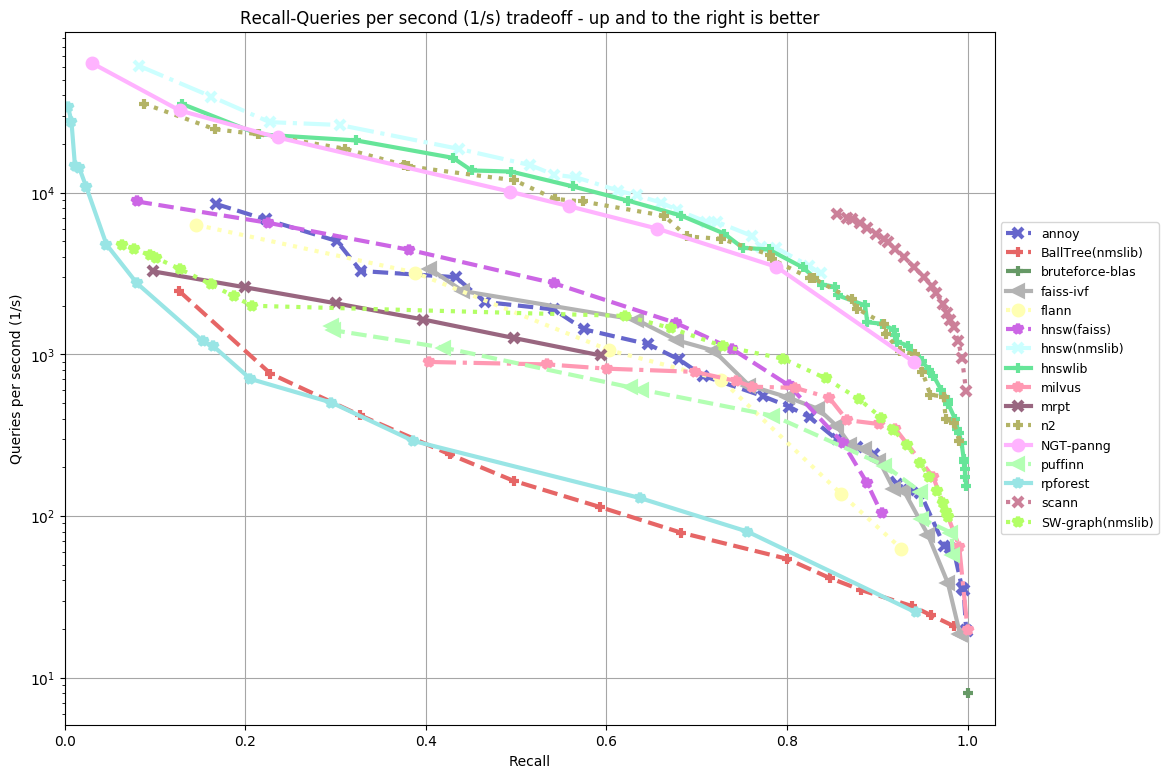
Do you have an opinion? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
howfairis
Have you heard of the Fair principes? Or perhaps you’ve generally thought about what makes software:
- Findable
- Accessible
- Interoperable
- Reusable
This week we highlight an atypical piece of research software, fair-software/howfairis that helps to make some of these abstract ideas more concrete, meaning giving you actionable feedback about the status of your GitHub repository. Why is it atypical? Because likely some folks would not consider this research software. But perhaps others would, because it’s a meta library that has promise to be used in a research context to better understand our software.

Do you have an opinion? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
autograd
Have you ever wanted to use automatic differentiation but your code is already written in numpy? Or just don’t want to learn another library? Today we are showcasing HIPS/autograd, which will allow you to do just that. That’s right, just write a function in numpy, and get all of its gradients for free.
We encourage you to contribute to the research software encyclopedia and annotate the respository:
statsmodels
Have you ever needed to run some flavor of linear regression, time series analysis, mixed model, or some other kind of analysis? This week we share a popular library that you may not know about, statsmodels/statsmodels, that provides an impressive list of features to make statistical computations (descriptive statistics and estimation and inference for statistical models) easy for you.
We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Ideogram.js
Visualization is a powerful tool to understand and explore data, but it’s often overlooked. In scientific visualization, the best libraries can allow a scientist to bring life to something that we otherwise might not be able to see. Thus, for the software showcase this week, we are proud to share Ideogram.js, a visualization library in JavaScript that can draw and animate genome-wide datasets.
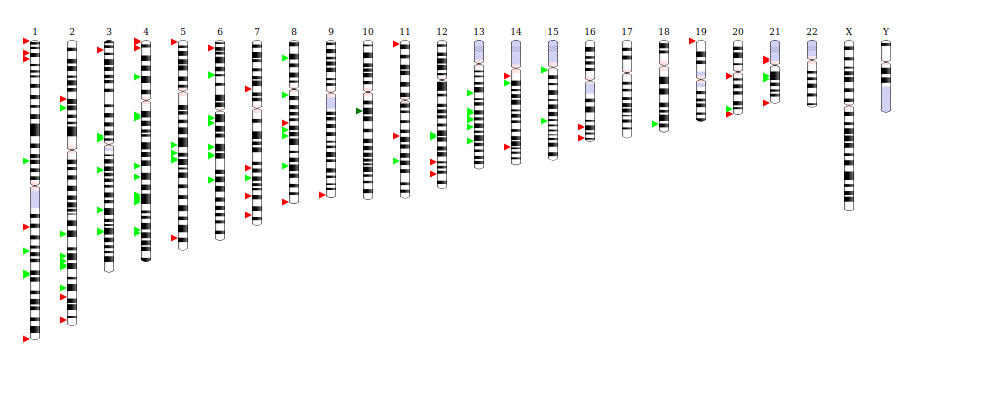
If you are familiar with the RSEPedia or software, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Singularity
Do you remember the reproducibility crisis? It’s a term so well-coined that it’s on Wikipedia, and although some of us possibly didn’t have awareness for it until 2014 or 2015, the term has been thrown around already for almost a decade. For the software showcase, we’ve featured workflow managers quite a bit, and it naturally must come to follow that we also feature container technologies, which often are the unit of operation passed around by the manager. In celebration of Google HPC Cloud Days featuring this container technology this week, the RSEPedia software showcase is proud to present Singularity for the showcase this week. Singularity, since 2015, has really taken the high performance computing, especially academic, world by storm by providing a means to run trusted containers on large research clusters with many users. It’s not the only, or a sure fire way to have reproducible science, but it sure is a good contender solution! Keep reading the following sections to learn more!

If you are already a container nerd, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Easybuild
Installing software from source is a non-trivial problem. That’s why we are a huge fan of package managers at the RSEpedia software showcase, and why this week we are featuring easybuild. Easybuild is especially pertinent to the research community because it’s intended to install and manage scientific software on High Performance Computing (HPC) resources. Keep reading the following sections to learn more!

If you are already an easybuilder, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Parsl
Have you ever had a workflow, or even an analysis script, and wanted to speed it up? Running something in parallel is probably an option that you considered. For this week’s software showcase we highlight Parsl, a parallel programming library for Python. If you know how to write a function in Python, there is a good chance you can extend it to be run with parsl, in parallel, either sequentially, with multicore (CPU, GPU, or accelerators) or multi-node MPI.

If you already know and love Parsl, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Codidact
As researchers and research software engineers, we want to synthesize knowledge. For programming help, for example, we might go to Stack Overflow and look for an upvoted answer. We might do a Google search and look for generic help. But what happens when we want to create our own knowledge base? What if we want to extend beyond a static documentation site? The following are events that are common in the research and research software communities:
I want to create a knowledge base
I really like Stack Overflow
Finds Stack Exchange
Fails to get through rounds of the community proposal process
Gives up or choose a non-optimal solution
For example, a research group might want simple community boards, tags, and up/down voting to identify best answers, but fail to get enough backing for Stack Exchange, and ultimately wind up with a Discourse site. Discourse is a fabulous community discussion site, but it doesn’t serve as a Stack Overflow substitute as well as we would want. It’s based around discussions and not “best answers to things,” and even with various voting plugins in place, when the content increases in size and you search for a specific question, you still need to parse through huge numbers of topics (posts). Even when you find one you are interested in, the discussion threads are hard to follow.
Is there an intermediate?
For a long time, it hasn’t been obvious that there exists an between Stack Exchange and Discourse. GitHub Discussions holds promise, but is still in beta and not available to everyone. The writer of this post (@vsoch) developed a Collaborative Knowledge Base prototype, but this idea was very different than Stack Overflow. It wasn’t until @vsoch discovered the repository for codidact/qpixel and started doing some development work. that a light went off - this is the intermediate tool.
![]()
This is a hugely interesting piece of software for discussion, because at it’s core, it’s isn’t explicitly made for research, or to directly solve a research question, but it can still serves a valuable role - sharing knowledge for a research community. If you already know about Codidact, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Nextflow
You know I’m all about those workflows, about those workflows, no trouble! I’m all about those workflows, about those workflows, no trouble!
Seriously, workflow managers and orchestration tools make the scientific computation world go round! Our showcase would simply not be complete without sharing Nextflow,
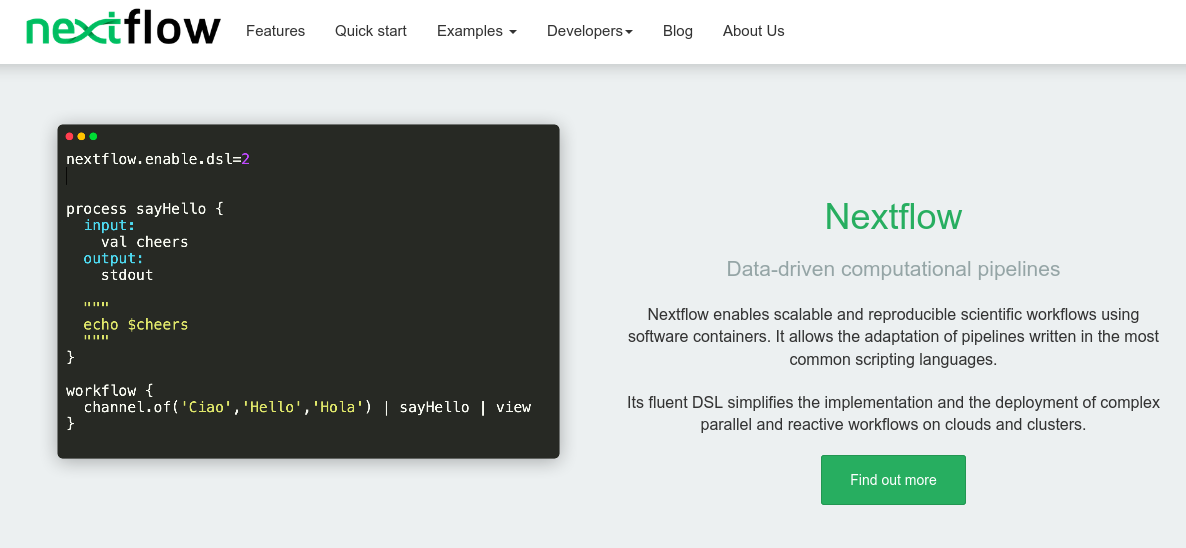
If you already know about NextFlow, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Scikit-image
This week the software showcase is celebrating image processing! While there are many domains that use it, and many software packages and languages to help, this week we celebrate scikit-image, which has you covered for many algorithms, tutorials, and examples.

If you already know about scikit-image, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Glue
Earlier this week, I was captured by this tweet.
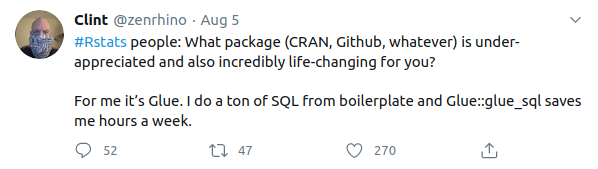
When you think about it, we take a lot of our software for granted. The fact that @zenrhino went out of his way to say “Hey, this library is great!” was a sign from the software gods that I needed to showcase it for the software showcase this week. Without further ado, let’s highlight the tidyverse/glue package! If you already know about glue, we encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
Chirps
We often take it for granted that when a large database exists, there are API clients that make it easy to digest in our language of choice. These libraries empower awesome research, but hardly get noticed. This is the case for ropensci/chirps a library in R that gives you programmatic access to the entire Climate Hazards Group InfraRed Precipitation with Station Data “CHIRPS” database.

And so we are going to showcase this quiet, and valuable tool this week! We encourage you to contribute to the research software encyclopedia and annotate the respository:
or learn more about it in the following sections.
Snakemake
This week for the sofware survey we are highlighting snakemake/snakemake, a workflow manager for Python that makes it easy to create and run a workflow from a high performance computing environment to a cloud provider.
or learn more about it in the following sections.
Sunpy
This week for the sofware survey we are highlighting sunpy/sunpy, a Python library for Solar Physics. SunPy handle both data analysis and visualization, and has quite a lovely logo!

I’ve made it big intentionally - do you notice anything? The middle is in fact a snake, and you can see his tongue too!
Annotate Away!
If you want to jump right in, you can:
or learn more about it in the following sections.
Spack
This week for the sofware survey we are highlighting spack/spack, a multi-platform package manager that builds and installs multiple versions and configurations of software. If you want to jump right in, you can:
or learn more about it in the following sections.
RTweets
Welcome to the first edition of the Software Survey! This is a weekly showcase of software will teach you a little bit about possibly new library, and request your quick annotation of the software for criteria and taxonomy categories. This week we are showcasing ropensci/rtweet
If you want to jump right in, you can:
or learn more about it in the following sections.
An Introduction to the Research Software Encyclopedia
The Research Software Encyclopedia
A community driven, open source strategy to derive context-specific definitions of research software.
What is research software? Simply stated, research software exists to support research. If we want to pursue better research, we then must understand it [3]. This leads us to ask some basic questions:
- What is research software?
- What are criteria that might help to identify research software?
- How do we organize research software?
While we could make an attempt to derive a holistic definition, this approach would be limited in not taking into account the context under which the definition is considered. For example, needing to define research software to determine eligibility for a grant is a different scenario than a journal needing to decide if a piece of software is in scope for publication, and both are different from an effort to study research software. In all cases, the fundamental need for a context-specific definition is not only important in these scenarios, but also for basic communication. If I am to call something research software, it’s essential that you know the criteria that I am using to consider it, how highly I consider each of those criteria, and a possibly classification that I am using to further drive my choices.
A Context Specific Definition
This effort, paired with the document that prompted its original thinking, takes the stance that it would be very challenging if not possible to create a single definition for research software. However, it’s very reasonable to derive criteria, or questions that we can easily answer, that can be used to determine a relative strength of a piece of software on a dimension of “strongly yes” to “strongly no.” We can also derive a taxonomy, or categorization of software types that might further filter this decision making. Both of these classifications, a scoring and location in the taxonomy, can then be transparently stated and used to answer if a specific piece of software is indeed research software. Importantly, while the choice of threshold for scoring and taxonomy filter is subjective, the classification and answers to the criteria are not. We have a transparent, methodic way to define pieces of software, and we leave some final definition up to the individual or group that warrants needing the definition.
Goals
1. Community Developed
It’s common for self-acclaimed “experts” or people in power to decide how things are going to be. This initiative aims to be completely transparent, open source, and community driven. Anyone can contribute to, or give feedback on the taxonomy, criteria, and even the software in the database. Annotation can happen with prompts from social media or slack communities, or in bulk on your local machine. We don’t view annotation as a task that would be suited for Mechanical Turk, or even necessary to do in bulk. Annotation takes time, and it should be fun. If we share one piece of software per week, not only will you be able to quickly give feedback and get on with your day, you’ll also potentially learn about a new tool that might be useful to you. Your contributions are then maintained in the repository history, and you get proper open source credit for your efforts.
2. Automated and Sustainable
It’s also often the case that efforts require grant funding, or long term funding of servers or databases to provide a resource. This initiative is hosted entirely on open source version control, and does not require any funding as long as these free services persist. This strategy is strong because even if the current version control service goes away (unlikely), since git paired with continuous integration (CI) is the backbone of the tooling, it would be very easy to set up the same repository elsewhere.
3. Understanding for Science
An understanding of the qualities of software that are required to support this research life-cycle is essential to continue and maximize the potential for discovery. In this light, research software is also about people, namely the developers and community that utilizes it. If we can better characterize this community to better understand how its needs map to research software, we can again better support scientific discovery.
[3] C. Goble, “Better Software, Better Research,” in IEEE Internet Computing, vol. 18, no. 5, pp. 4-8, Sept.-Oct. 2014, doi: 10.1109/MIC.2014.88.
How does it work?
By way of separation of tools to allow for participation or development in the subset that is of interest to you, we achieve a holistic space of software, database, and application programming interfaces.
- Taxonomy and Criteria are served programaticaly from the Research Software Engineering (rseng) repository.
- Database: the Research Software Encyclopedia drives generation and update of the database served at rseng/software.
- Update is automated using GitHub Workflows.
- Annotate directly via the repository interface or by opening an issue or in bulk on your local machine
- Use the api to see repos, taxonomy, and criteria
- Use the rse tool to manage a software database, create an interface, or export metrics.
How can I get involved?
Community effort means that we are looking for your contributions! And there are so many ways to get involved!
1. Work on the Manuscript
There is a manuscript in progress that your feedback and contribution would be greatly valued on! If you contribute, please add your name as a co-author. We are planning a few small talks in the next few months, and will aim for submitting somewhere after that.
2. Taxonomy and Criteria
The taxonomy and criteria are served programatically from the Research Software Engineering (rseng) repository. If you want to contribute to either of those, that’s the repository you should contribute to.
3. Research Software Encyclopedia
The rse management tool along with it’s annotation and general interfaces is the core
software that powers most of what we’ve discussed above. You can contribute or give feedback to rse to make the library better.
4. Software Database
The software database itself is hosted at rseng/software. Whether you annotate one software entity weekly via social media prompt or clone the repository for bulk annotation, your contributions are maintained in version control to always proudly show you as a contributor. And of course any other feedback that you might have, please post issues, and questions on any of the issue boards associated with the repos above!
Annotate your Software
In this tutorial, we will walk through using the Research Software Encyclopedia (rse) to annotate software in the
rseng/software database with
criteria and taxonomy items.
Showcase your Software
In this tutorial, we will walk through using the Research Software Encyclopedia (rse) with criteria hosted here to generate a static interface to display your research software.
Introducing Research Software Criteria and Taxonomy
Welcome to Rseng, an endpoint to find research software criteria and taxonomy. This interface deploys a versioned taxonomy and set of criteria for research software.