bluesky
This week for the Research Software Encyclopedia Software Showcase we move into the world of experiment orchestration and data management. This includes features like:
- streaming data
- metadata
- cross-hardware compatibility
- interruption recovery
- suspend or resume
- exportable formats
- customization
- interface with scientific python
If you too are like me and have never tried a library like this, I recommend starting with the tutorial.
Are you already familiar with this software? We encourage you to contribute to the research software encyclopedia and annotate the respository:
otherwise, keep reading!
- What is bluesky?
- How do I cite it?
- How do I get started?
- How do I contribute to the software survey
- Where can I learn more?
What is bluesky?
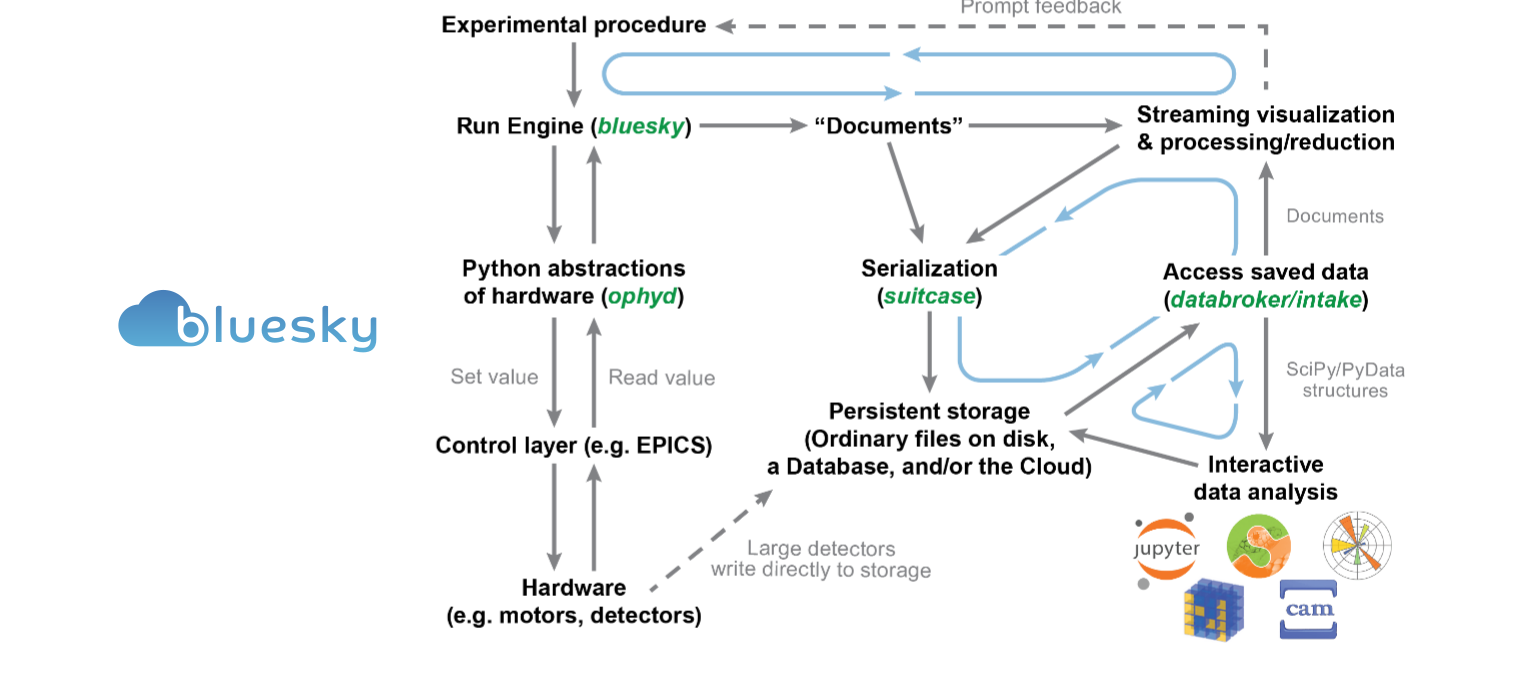
BlueSky is actually two things - the BlueSky Project is a community cenered around experimental science, and bluesky is a software library that happens to belong to this project. If you look at the image in the post above, it shows how different libraries (in blue) work together to help you with your experiments. The BlueSky software (one of those libraries) is specifically the orchestration component. It allows you to:
- describe your experiment logic without needing to think about hardware
- interact with (collect) streaming data
- preserve metadata
- pause or resume experiments
If you are not an instrumentalist or you’ve never worked with hardware, this library might seem very
different from what you usually see. This is exactly why we chose it for the RSEPedia software
showcase this week. Let’s walk through a short example from the tutorial. We can start
and assume that a Run Engine has
been configured for us. From the tutorial, it looks like this controls data storage
and visualization. Once we have a run engine (RE) we can run an experimental plan using it. Let’s first read a set of simulated
detectors. We can import them from the ophyd library:
from ophyd.sim import det1, det2 # two simulated detectors
Now let’s import the bluesky plan to count, which is what we call reading the detectors. We will hand this plan to our run engine (RE)
from bluesky.plans import count
dets = [det1, det2] # a list of any number of detectors
RE(count(dets))
# five consecutive readings
RE(count(dets, num=5))
# five sequential readings separated by a 1-second delay
RE(count(dets, num=5, delay=1))
# a variable delay
RE(count(dets, num=5, delay=[1, 2, 3, 4]))
Here is what output might look like:
Transient Scan ID: 1 Time: 2020-12-18 01:45:37
Persistent Unique Scan ID: 'af3aa0bc-58e8-4022-8899-9c7ef93c31f4'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | det2 | det1 |
+-----------+------------+------------+------------+
| 1 | 01:45:37.0 | 1.213 | 0.000 |
+-----------+------------+------------+------------+
generator count ['af3aa0bc'] (scan num: 1)
Out[2]: ('af3aa0bc-58e8-4022-8899-9c7ef93c31f4',)
This example is taken right from the tutorial and of course hugely fails to do justice for what the library can do! It’s recommended to try it out yourself.
Why is it useful?
When doing some kind of analysis with living, changing data, it’s important to not only be able to retrieve it programatically, but also to be able to freeze the version of the data that you use. By downloading an entire snapshot in time, this makes it easy to do your analysis over the dataset without having it change on you!
How do I cite it?
There is an applied paper that introduces the library:
@inproceedings{10.1117/12.2569000,
author = {Maksim S. Rakitin and Abigail Giles and Kaleb Swartz and Joshua Lynch and Paul Moeller and Robert Nagler and Daniel B. Allan and Thomas A. Caswell and Lutz Wiegart and Oleg Chubar and Yonghua Du},
title = {Introduction of the Sirepo-Bluesky interface and its application to the optimization problems},
volume = {11493},
booktitle = {Advances in Computational Methods for X-Ray Optics V},
editor = {Oleg Chubar and Kawal Sawhney},
organization = {International Society for Optics and Photonics},
publisher = {SPIE},
pages = {209 -- 226},
keywords = {Sirepo, SRW, Bluesky, Databroker, Ophyd, optimization, simulations},
year = {2020},
doi = {10.1117/12.2569000},
URL = {https://doi.org/10.1117/12.2569000}
}
And an example of how the library was included in a strategic plan.
How do I get started?
How do I contribute to the software survey?
or read more about annotation here. You can clone the software repository to do bulk annotation, or annotation any repository in the software database, We want annotation to be fun, straight-forward, and easy, so we will be showcasing one repository to annotate per week. If you’d like to request annotation of a particular repository (or addition to the software database) please don’t hesitate to open an issue or even a pull request.
Where can I learn more?
You might find these other resources useful:
- The Research Software Database on GitHub
- RSEpedia Documentation
- Google Docs Manuscript you are invited to contribute to.
- Annotation Documentation for RSEpedia
- Annotation Tutorial in RSEng docs
For any resource, you are encouraged to give feedback and contribute!
Recent Posts
- Posted on 21 Mar 2021
- Posted on 07 Mar 2021
- Posted on 21 Feb 2021
- Posted on 21 Feb 2021